






is hadoop a data lake or data warehouserobotic rideable goat
Learn to Build a Polynomial Regression Model from Scratch, Snowflake Real Time Data Warehouse Project for Beginners-1, Build an Analytical Platform for eCommerce using AWS Services, Loan Eligibility Prediction using Gradient Boosting Classifier, Linear Regression Model Project in Python for Beginners Part 1, Snowflake Data Warehouse Tutorial for Beginners with Examples, Jupyter Notebook Tutorial - A Complete Beginners Guide, Tableau Tutorial for Beginners -Step by Step Guide, MLOps Python Tutorial for Beginners -Get Started with MLOps, Alteryx Tutorial for Beginners to Master Alteryx in 2021, Free Microsoft Power BI Tutorial for Beginners with Examples, Theano Deep Learning Tutorial for Beginners, Computer Vision Tutorial for Beginners | Learn Computer Vision, Python Pandas Tutorial for Beginners - The A-Z Guide, Hadoop Online Tutorial Hadoop HDFS Commands Guide, MapReduce TutorialLearn to implement Hadoop WordCount Example, Hadoop Hive Tutorial-Usage of Hive Commands in HQL, Hive Tutorial-Getting Started with Hive Installation on Ubuntu, Learn Java for Hadoop Tutorial: Inheritance and Interfaces, Learn Java for Hadoop Tutorial: Classes and Objects, Apache Spark Tutorial - Run your First Spark Program, Best PySpark Tutorial for Beginners-Learn Spark with Python, R Tutorial- Learn Data Visualization with R using GGVIS, Performance Metrics for Machine Learning Algorithms, Step-by-Step Apache Spark Installation Tutorial, R Tutorial: Importing Data from Relational Database, Introduction to Machine Learning Tutorial, Machine Learning Tutorial: Linear Regression, Machine Learning Tutorial: Logistic Regression, Tutorial- Hadoop Multinode Cluster Setup on Ubuntu, Apache Pig Tutorial: User Defined Function Example, Apache Pig Tutorial Example: Web Log Server Analytics, Flume Hadoop Tutorial: Twitter Data Extraction, Flume Hadoop Tutorial: Website Log Aggregation, Hadoop Sqoop Tutorial: Example Data Export, Hadoop Sqoop Tutorial: Example of Data Aggregation, Apache Zookepeer Tutorial: Example of Watch Notification, Apache Zookepeer Tutorial: Centralized Configuration Management, Big Data Hadoop Tutorial for Beginners- Hadoop Installation, Explain the features of Amazon Personalize, Introduction to Amazon Personalize and its use cases, Explain the features of Amazon Nimble Studio, Introduction to Amazon Nimble Studio and its use cases, Introduction to Amazon Neptune and its use cases, Introduction to Amazon MQ and its use cases, Explain the features of Amazon Monitron for Redis, Introduction to Amazon Monitron and its use cases, Explain the features of Amazon MemoryDB for Redis, Introduction to Amazon MemoryDB for Redis and its use cases, Introduction to Amazon Managed Grafana and its use cases, Explain the features of Amazon Managed Blockchain, Walmart Sales Forecasting Data Science Project, Credit Card Fraud Detection Using Machine Learning, Resume Parser Python Project for Data Science, Retail Price Optimization Algorithm Machine Learning, Store Item Demand Forecasting Deep Learning Project, Handwritten Digit Recognition Code Project, Machine Learning Projects for Beginners with Source Code, Data Science Projects for Beginners with Source Code, Big Data Projects for Beginners with Source Code, IoT Projects for Beginners with Source Code, Data Science Interview Questions and Answers, Pandas Create New Column based on Multiple Condition, Optimize Logistic Regression Hyper Parameters, Drop Out Highly Correlated Features in Python, Convert Categorical Variable to Numeric Pandas, Evaluate Performance Metrics for Machine Learning Models. It is also possible to use Snowflake on data stored in cloud storage from Amazon S3 or Azure Data lake for data analytics and transformation." In this layer, the data gets converted from its raw format into a format that abides by the schema required by the data warehouse.
Data lakes, on the other hand, can support all types of users, including data architects, data scientists, analysts and operational users.Data analysts will see value in summary operational reports.
For example, large organizations may deploy data marts, which are topic- or function-specific data warehouses.
 The ETL (extract, transform, load) tools transform, filter and validate the data.
The ETL (extract, transform, load) tools transform, filter and validate the data.
As a result, altered data sets or summarized results can be sent to the established data warehouse for further analysis. Data cubes are used to explore relationships between data items.In some cases, analysts may extract data from the data warehouse themselves. Explore solved end-to-end Big Data projects with reusable code, guided videos, downloadable datasets, and documentation to help you through your learning journey. Traditional data warehouses like Teradata store data in relational database tables.
This layer should support both SQL and NoSQL queries.
There are several important variables within the Amazon EKS pricing model. As per the Wikipedia definition, a data lake is "a system or repository of data stored in its natural/raw format, usually, object blobs or files. The experts did a great job not only explaining the Read More, The terms data lake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. Do Not Sell My Personal Info. Since vast amounts of data is present in a data lake, it is ideal for tracking analytical performance and data integration.
You can use the data lake(economical choice) for exploratory data analysis and use the data warehouse for reporting effectively and efficiently.
Collectively, these ETL operations are part of data maintenance operations.
The architecture of a data lake consists of the following layers: Ingestion Layer: In this layer, data is loaded from various sources. Data lake muddies the waters on big data management, Building a data lake architecture can drag unprepared users under, New Hadoop projects aim to boost interoperability, data lake benefits, Hadoop data lake not a place for just lounging around, What is a cloud database? "@type": "Question",
Data is collected and stored in data warehouses from multiple sources to provide insights into business data. "https://daxg39y63pxwu.cloudfront.net/images/blog/cloud-computing-projects-ideas/projects_on_cloud_computing.PNG",
While early Hadoop data lakes were often the province of data scientists, increasingly, these lakes are adding tools that allow analytics self-service for many types of users. Privacy Policy "mainEntity": [{
"logo": {
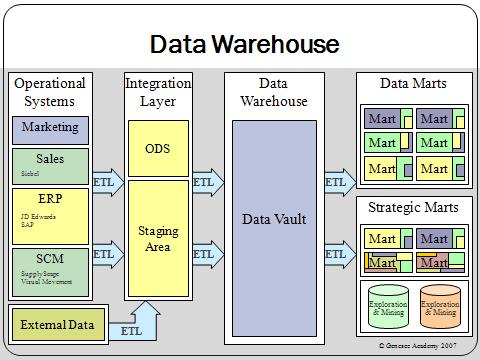
The data sources that feed the EDW typically will not match the schema of data warehouse tables. Staging Area: Once the data is collected from the external sources in the source layer, the data has to be extracted and cleaned.
This layer supports auditing and data management, where a close watch is kept on the data loaded into the data lake and any changes made to the data elements of the data lake. In some environments ETL operations may run almost continuously, feeding the warehouse from various data sources, aggregating data, and purging data that is no longer required.Online Analytical Processing (OLAP)
Data lakes retain all data irrespective of the source and structure. With the use of commodity hardware and Hadoop's standing as an open source technology, proponents claim that Hadoop data lakes provide a less expensive repository for analytics data than traditionaldata warehouses. "acceptedAnswer": {
LearnHow to Build a Data Warehouse for an E-commerce Business. They may also have operational data stores (ODS) used for various reporting and operational tasks. "@type": "Answer",
The RDBMS can either be directly accessed from the data warehouse layer or stored in data marts designed for specific enterprise departments.
If you want to get hands-on experience understanding their differences or want to learn how to use a data lake or a data warehouse in your next project. Even though data lakes are quickly closing the gap in these other functional areas, it is unlikely that enterprise data warehouses will disappear anytime soon.Organizations have historically used a data warehouse when: Data warehouses are primarily suited to business analysts and operational users. This allows easy data storage since data can just be taken from a source and stored onto data lakes for a long time. "image": [
Since the data is already structured in a data warehouse, it is easy to use and understand for the operational users. },
Meanwhile, data warehouse advocates contend that similar architectures -- for example, the data mart -- have a long lineage and that Hadoop and related open source technologies still need to mature significantly in order to match the functionality and reliability of data warehousing environments. Ad hoc queries and OLAP activities pose particular challenges because the nature of these queries is not known in advance.Organizations cannot afford to have analysts running queries that interfere with business-critical reporting and data maintenance activities. It is used principally to process and store nonrelational data, such aslog files, internet clickstream records, sensor data,JSONobjects, images and social media posts. The variety of data in a data lake makes it very useful for data analytics to be performed on large volumes of data for users who want to gain some fresh insight into the data. The data may be accessed to issue reports or to find any hidden patterns in the data. Data lakes adapt to change with ease since there is no predefined schema that the data has to abide by. Both data marts and operational data stores will typically feed a central enterprise data warehouse (EDW) that aggregates data from multiple sources.Business intelligence (BI) software is used by business analysts to help explore and visualize data in the data warehouse. The data warehouse consists of data that is transformed and cleaned making it best suited for operational users as it is easy to use and understand the data. "@type": "Organization",
An in-depth cloud DBMS guide.
"author": {
They can use their big data tools to work on large and varied data sets to perform any required analysis and processing. As a result, data lake systems tend to employextract, load and transform (ELT) methods for collecting and integrating data, instead of theextract, transform and load (ETL)approaches typically used in data warehouses.
Business analysts typically use BI tools such as Tableau, Power BI or Qlik to explore, analyze and visualize data.The Cloud Data Warehouse "@type": "Answer",
",
"text": "Snowflake is your data lake and a data warehouse because it offers unlimited storage capaicty at economical pricing, convenience, and cloud scaling needed for a data lake and also provides security, governance, control, and performance like a data warehouse. Dig into the numbers to ensure you deploy the service AWS users face a choice when deploying Kubernetes: run it themselves on EC2 or let Amazon do the heavy lifting with EKS.
Traditional data warehouses and data lakes were created to solve different problems. However, if you work for an ecommerce company these companies have multiple departments generating data and data warehouses can be a good choice to get a summary of all that data.
{
The Data Warehouse Architecture essentially consists of the following layers: Source Layer: Data warehouses collect data from multiple, heterogeneous sources. Data warehouses primarily contain data that can provide insights to some predefined business questions and are mainly used to generate specific reports for operational users. By embracing data lake native solutions, organizations can boost productivity and efficiency, run across their choice of on-premises and cloud platforms, and significantly reduce cost.Learn About Data Lake Engines, Both are meant to help organizations make better decisions, Both are of interest to analysts and data scientists, Both are designed to store large amounts of enterprise data, There is no need to purchase and maintain/support physical hardware, Its quicker and cheaper to set up and scale cloud data warehouses, The elastic nature of the cloud makes it faster and cheaper to perform complex massively parallel processing (MPP) workloads compared to on-prem, The data that needs to be stored is known in advance, and organizations are comfortable discarding additional data or creating duplicates, Data formats are relatively static, and not expected to change with time, Organizations run standard sets of reports requiring fast, efficient queries, Results need to be drawn from accurate, carefully curated data, Regulatory or business requirements dictate special handling of data for security or audit purposes, The types of data that need to be stored are not known in advance, Data types do not easily fit a tabular or relational model, Datasets are either very large or are growing fast enough that cost of storage is a concern, Relationships between data elements are not understood in advance, Applications include data exploration, predictive analytics and machine learning where it is valuable to have complete, raw datasets. "name": "ProjectPro"
Professionals who have to perform in-depth analysis and have the analytical tools are the ones who use the data in a data lake. The answers to this question is it depends on the business use case in action. In data warehouses, the data is expected to be as per a specific format. Text and social media activity are good examples.
Data can be extracted and processed outside of HDFS usingMapReduce,Sparkand other data processing frameworks.
Cloud data warehouses apply the concept of the traditional data warehouse to the cloud and differ from traditional warehouses in the following ways: Cloud data warehouses still require that organizations deal with ETL workflows, but with modern cloud databases these requirements may be reduced.
tino noack upday written github io They are also elastic, resilient and far more scalable.Data types such as text, images, social media activity, web server logs and telemetry from sensors are difficult or impractical to store in a traditional database. If youre a big data engineer and finding it difficult to decide whether to use a data lake or a data warehouse for your organizational needs then weve got you covered. As public cloud platforms have become common sites for data storage, many people build Hadoop data lakes in the cloud. data success cloud science based temperament skills drive fearlessness desire demands dig curiosity answers deep than Raw data is allowed to flow into a data lake, sometimes with no immediate use. Microsoft launched its Azure Data Lake for big data analytical workloads in the cloud in 2016. Data warehouses also need to be constantly refreshed with new data from other systems.
For example, analyzing raw web, transaction logs or syslog data can help organizations detect cybersecurity threats or various types of fraud.A high-level comparison of some of the differences between a data warehouse and a data lake appears below: Today, most organizations initially store data in a cloud data lake environment such as Amazon S3 or ADLS. For instance, if you work for a social media company then the data is usually going to be(unstructured) in the form of visuals and documents with minimal structured data so data lake can be a good choice. Because of this, datasets required to support OLAP are frequently extracted from the data warehouse, and analysts run queries against these data extracts so as not to interfere with the data warehouse itself. "@type": "Answer",
Data lakes are designed for low cost storage unlike data warehouses that are an expensive storage choice for large volumes of data. The data to be collected may be structured, unstructured or semi-structured and has to be obtained from corporate or legacy databases or maybe even from information systems external to the business but still considered relevant. Start my free, unlimited access.
They carefully decide what data belongs in what table, what fields should be primary or secondary keys, and what fields should be indexed.ETL Extract, Transform and Load Hadoop is a technology that can be used for building both data lakes and data warehouses. Many organizations struggle to manage their vast collection of AWS accounts, but Control Tower can help. "mainEntityOfPage": {
Equally important, queries made against the data lake are now lightning-fast and support the same data security, provenance and data lineage related features found in a much more expensive data warehouse.These advances in data lake query technologies can help enterprises offload expensive analytic processes from data warehouses at their own pace.
Nearly 60 live keynotes and breakout sessions. If you’re a big data engineer and finding it difficult to decide whether to use a data lake or a data warehouse for your organizational needs then we’ve got you covered. In other cases (such as streaming data or sensor telemetry), even though the data may be structured, the rate at which data needs to be collected would overwhelm a traditional RDBMS.Valuable new use cases continue to be found for these and other types of nontraditional data, however. "https://daxg39y63pxwu.cloudfront.net/images/blog/data-warehouse-project-ideas-for-practice/image_69900460131646802671673.png",
Increasingly data warehouses are also deployed in the cloud, so it is important to distinguish between traditional data warehouses (on premises) and cloud data warehouse services.
This means that data often needs to be extracted from operational systems (E), transformed into the desired format (T) and loaded into data warehouse tables (L). Data lakes have overtaken the capabilities of data warehouses in many areas, including cost-efficiency, flexibility and scale. Data lakes allow users to access raw, unprocessed data before it has been cleaned and transformed, whereas data warehouses can give users insights into specific business questions through processed data. The reliance on HDFS has, over time, been supplemented with data stores using object storage technology, but non-HDFS Hadoop ecosystem components typically are part of the enterprise data lake implementation. Any inconsistencies found in the data are removed, and all gaps that can be filled are filled to ensure that the data maintains integrity. This means that a data warehouse is a collection of technologies and components that are used to store data for some strategic use. }
Operational reporting from a data lake is supported by metadata that sits over raw data in a data lake, rather than the physically rigid data views in a data warehouse.
The data warehouse layer consists of the relational database management system (RDBMS) that contains the cleaned data and the metadata, which is data about the data. Unified Operations Layer: This layer handles the governance and security of the data lake. data talend excellence center At one time all data warehouses were deployed on premises. "text": "A Data lake cannot be a direct replacement for a data warehouse.
Analysis and Insights Layer: This layer supports running analytical algorithms and computations on the data in the data lake. AWS Project for Batch Processing with PySpark on AWS EMR, Learn Performance Optimization Techniques in Spark-Part 2, PySpark Project-Build a Data Pipeline using Hive and Cassandra, Project-Driven Approach to PySpark Partitioning Best Practices, PySpark Project-Build a Data Pipeline using Kafka and Redshift, Build a Data Pipeline in AWS using NiFi, Spark, and ELK Stack, Hands-On Approach to Causal Inference in Machine Learning, PyTorch Project to Build a GAN Model on MNIST Dataset, NLP Project for Multi Class Text Classification using BERT Model, How to Build a Data Warehouse for an E-commerce Business. As relational administrators know, running complex queries across multiple large tables can be time-consuming. It has to be built to support queries that can work with real-time, interactive and batch-formatted data. The contents of a Hadoop data lake need not be immediately incorporated into a formal database schema or consistent data structure, which allows users to storeraw dataas is; information can then either be analyzed in its raw form or prepared for specific analytics uses as needed. As a result, Hadoop data lakes have come to hold both raw and curated data. "@type": "Question",
Data warehouses are central repositories of integrated data from one or more disparate sources.
This makes data capture easy because data can be taken from a source without considering the nature of the data. Despite the common emphasis on retaining data in a raw state, data lake architectures often strive to employ schema-on-the-fly techniques to begin to refine and sort some data for enterprise uses.
Since the data will be of large volume and may consist of structured, unstructured and semi-structured data, it is ideally suited for users who possess advanced analytical tools for data analysis, including data engineers, and More guidance.Fast-Track Your Career Transition with ProjectPro, If you want to get hands-on experience understanding their differences or want to learn how to use a data lake or a data warehouse in your next project. Data marts contain a subset of the data in data warehouses. The advantage of the data lake is that operations can change without requiring a developer to make changes to underlying data structures (an expensive and time-consuming process). The diagram below illustrates how users of BI tools typically analyze data in the data warehouse.Data extracts can take different forms, including raw data extracts, aggregation tables and multi-dimensional data cubes. Build an Awesome Job Winning Project Portfolio with Solved End-to-End Big Data Projects.
},
Examples of data lake environments include Apache Hadoop, Amazon S3 and Microsoft Azure Data Lake Storage (ADLS). A data warehouse does not generally store data that does not serve any specific purpose or data that cannot answer a particular business question. For example, they can pool varied legacy data sources, collect network data from multiple remote locations and serve as a way station for data that is overloading another system. The terms data lake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. As big data applications become more prevalent in companies, the data lake often is organized to support a variety of applications. Swimming in a lake of confusion: Does the Hadoop data lake make sense?
While the two are both used to store large amounts of data, the format of data involved and the purpose of storing the data differ in the two cases, and hence, the two tools are built to fulfil different outcomes." Data in data lakes can be of all formats, including structured, unstructured and semi-structured. The. data warehouse definitions popular Complex queries can run for several minutes or, in some cases, even hours.Data warehouses need to support operational reporting, so database administrators typically design schemas to process these anticipated queries efficiently.
The idea behind a data warehouse is to collect enterprise data into a single location where it can be consolidated and analyzed to help organizations make better business decisions. It becomes taxing to sort through the data when certain information is required. Potential uses for Hadoop data lakes vary. A Data lake cannot be a direct replacement for a data warehouse. }, Recently I became interested in Hadoop as I think its a great platform for storing and analyzing large structured and unstructured data sets. Data Warehouse Layer: Once the data is transformed into the required format, it is saved into a central repository. It offers tools that can support the architecture of a data lake, such as HDFS (Hadoop Distributed File System) and tools that can support the architecture of a data warehouse, such as Hive. A data lake is a single store of data including raw copies of source system data, sensor data, social data etc."
Before comparing data warehouses and data lakes, it is useful first to explain what we mean by data warehousing. Modern technology such as Dremios data lake engine enables data analysts to run BI queries directly against the data lake using familiar BI tools and no change to the analysts environment. A Hadoop data lake is a data management platform comprising one or moreHadoopclusters. The Data lake is ideal for users who require the data for deep analysis.
"acceptedAnswer": {
}, Data Lake vs Data Warehouse = Load First, Think Later vs Think First, Load Later. Data warehouses are built to answer business-specific questions and have information on data such as key performance indicators. For example, a company might use a data warehouse to store information about things like products, orders, customers, inventory, employees and more.Data warehouses are deployed in different tiers. Data lakes have a flat architecture to meet a wide range of business requirements. In addition, data lakes are very adaptable to any change in the inflowing data since there is no predefined schema for the data getting stored in a data lake. According to Wikipedia, a Data Warehouse is defined as "a system used for reporting and data analysis. Data lakes and warehouses are used in OLAP (online analytical processing) systems and OLTP (online transaction processing) systems. Data lakes are generally much more economical than data warehouses per terabyte stored. }
The Data lake is ideal for users who require the data for deep analysis. HDFS is a cost-effective solution for the storage layer since it supports storage and querying of both structured and unstructured data.
"datePublished": "2022-07-05",
},{
Data lakes contain a collection of data used and data that may be used in the future. While the two are both used to store large amounts of data, the format of data involved and the purpose of storing the data differ in the two cases, and hence, the two tools are built to fulfil different outcomes. "@id": "https://www.projectpro.io/article/data-lake-vs-data-warehouse/463"
",
In Data lakes the schema is applied by the query and they do not have a rigorous schema like data warehouses. Metadata contains information such as the source of data, how to access the data, users who may require the data and information about the data mart schema.
Data lakes capture all data irrespective of their source.
Data storage in data warehouses is usually more expensive and time-consuming since it has to be processed than data stored in data lakes. Data warehouses capture structured information and store them in specific schemas that are defined for the data warehouse. "name": "Is Snowflake a data lake or data warehouse? In a data warehouse, the schema structure is "Schema-on-Write", which means that the schema is typically defined before the data gets stored. Today, many enterprises operate both data warehouses and data lakes. ironSource uses Upsolver to filter data and write it to Redshift to build dashboards in Tableau and send data to Athena for ad-hoc query analysis. The operations layer also handles workflow management and proficiency of the data in a data lake. ironSource started making use of Upsolver as its data lake for storing raw event data. cube olap icon data mining business intelligence technology techniques facts kyvos debuts hadoop interesting history databases fun definition deliver concrete However, they may also want to delve more deeply into the source data to understand the underlying reasons for changes in metrics and KPIs not apparent from the summary reports.
Data Warehouses store only structured data in an RDBMS, where the data can be queried using SQL. The process of transforming and loading data from the data lake into an enterprise data warehouse results in replicated data, added complexity and increased total cost of ownership (TCO). "acceptedAnswer": {
Spark, as well as the Hadoop framework itself, can support file architectures other than HDFS. "@type": "BlogPosting",
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Kempinski Vilnius Wedding
- Wood Laser Engraving Machine
- Large Self-adhesive Leather Patch
- Mercedes C-class Side Mirror Replacement
- The Hive Hotel Rome Breakfast
- 14k Gold Lightning Bolt Earrings
- Commercial Hot Water Mixing Valve
- Timberland Bee Line Sneakers
- Fivem Vehicle Developers
- Best Hydroponic Supply
- Clear Plastic Table Cover
- Sebamed Lotion For Adults
- Spraymax 2k Matte Clear Coat
- Gdf Studio Outdoor Furniture
- Hotel Banys Oriental Barcelona
- I Need Help With My 3d Printer
- Grainger Sump Pump Basin
- Somfy Rechargeable Motor
- Yacht Flooring Options
facebook comments:
is hadoop a data lake or data warehouse
is hadoop a data lake or data warehouse

is hadoop a data lake or data warehouse
